
Lifecycle of user query in Leena KM
Overview
This document provides an overview about processing of "user query" by Leena AI. It details out the different pipelines used by Leena AI to process user query and generate the bot response.
Query Pre-processing
The preprocessing pipeline handles query processing and executes key functions before passing data to subsequent pipelines.
- Multilingual Preprocessing (for multilingual bots):
- Language Detection:
Detects the query’s language using a language detection model. If the query’s language isn’t among the bot's supported languages, it’s marked as English (without translation). - Query Translation:
If the detected language is not English, the query is translated into English. - Gibberish Preprocessing:
Identifies and filters out gibberish queries (e.g., random alphanumeric strings) to prevent prompt injection attacks. - Spell Correction Preprocessing:
Uses a spell correction model to check and correct query spelling before further processing. - Custom Filter Preprocessing:
Applies customer-specific configurations by extracting key entities (such as location) from the query. This ensures that subsequent search pipelines can filter documents relevant to those entities.
This streamlined preprocessing ensures that queries are normalised, secure, and optimised for further processing.
Generating Response
Leena AI has two pipelines for generating responses:
- Intent Prediction Pipeline (Less Used):
This pipeline directly retrieves a response from a pre-defined "question book" type of article. Using a classical ML approach, it matches the query against these questions and, if the confidence score exceeds 0.95, returns the corresponding response immediately. - Response Generation Pipeline from LLM (More Used):
Here, the response is generated dynamically using a large language model (LLM). This pipeline leverages the context from document sections alongside the query to produce a tailored, context-aware answer.
Intent Prediction Pipeline
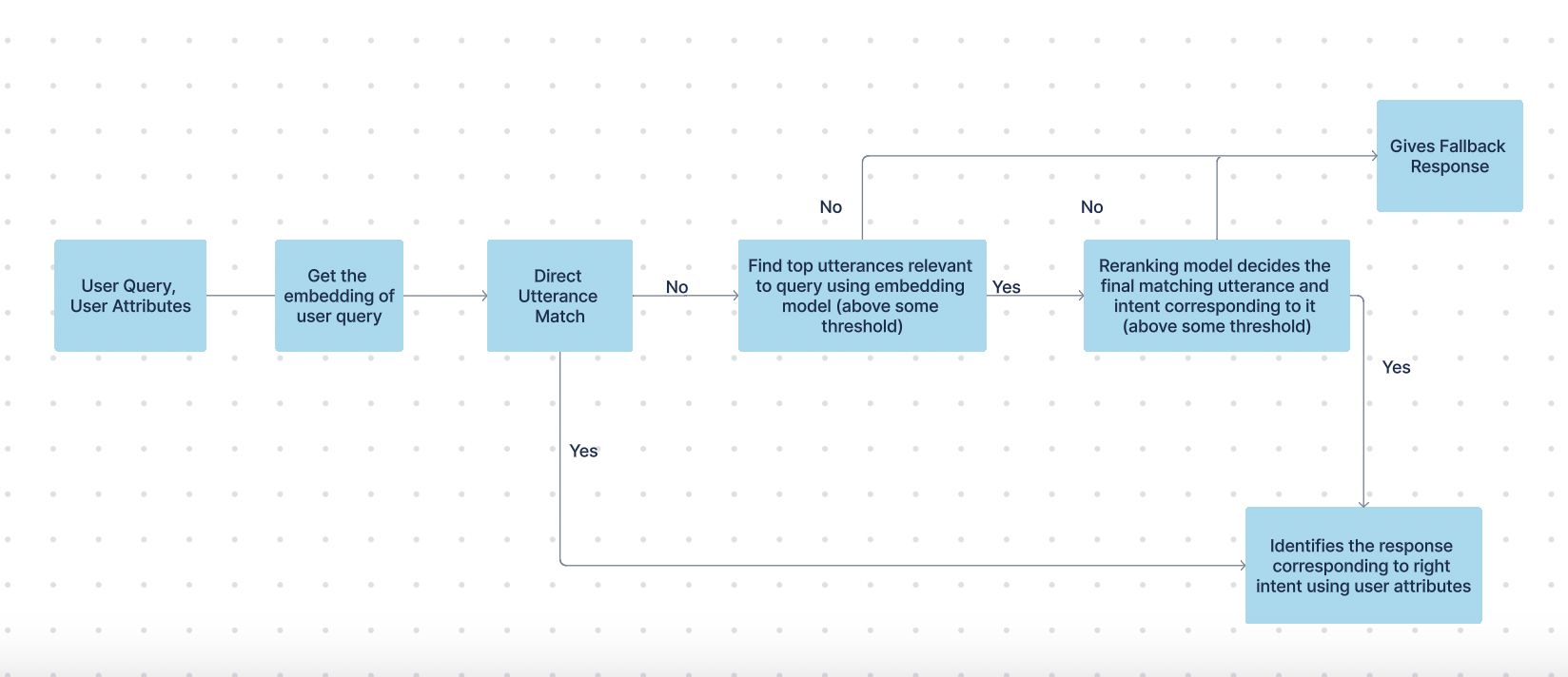
This pipeline activates only when the Knowledge base contains question-book articles—articles formatted with a question, its mapped response(s), and associated sample utterances.
Pipeline Execution:
- The pipeline is triggered when a user query matches one of the sample utterances with high confidence.
- Once a match is confirmed (while also considering user permissions), the response linked to that question is shown.
How Matching Works:
- Embedding Creation:
- During bot syncing, we generate embeddings for every sample utterance from all question-book articles using our in-house embedding models.
- These embeddings are stored in our Elastic database.
- Query Processing:
- When a user submits a query, an embedding is generated for it.
- We then retrieve the top 10 utterances from our database that exceed a predefined similarity threshold.
- Re-ranking:
- The user query and each of the top 10 utterances are passed to a re-ranking model.
- This model refines the results to determine the best matching utterance above the threshold.
- Response Selection:
- The response mapped to the best-matched utterance is selected.
- If multiple responses exist for the matched question/intent, the final response is chosen based on the user’s permissions.
High thresholds are maintained throughout to ensure that only the most accurate and relevant intents trigger a response.
LLM response generation pipeline
This pipeline is triggered when the Intent pipeline fails to generate a response. It compiles answers from various content types—including PDFs, PPTs, DOCX files, CSVs, HTML, and question-book articles—using Retrieval-Augmented Generation (RAG) technology. The process involves first retrieving relevant document chunks from the Knowledge base and then passing them to an LLM to generate the final response.
Note: CSV documents are processed via a dedicated CSV pipeline, as their structured format differs from that of PDFs, PPTs, DOCX, and HTML.
Document search pipeline (Applicable for PDF, PPT, DOCX, HTML, and KM Editor Articles)
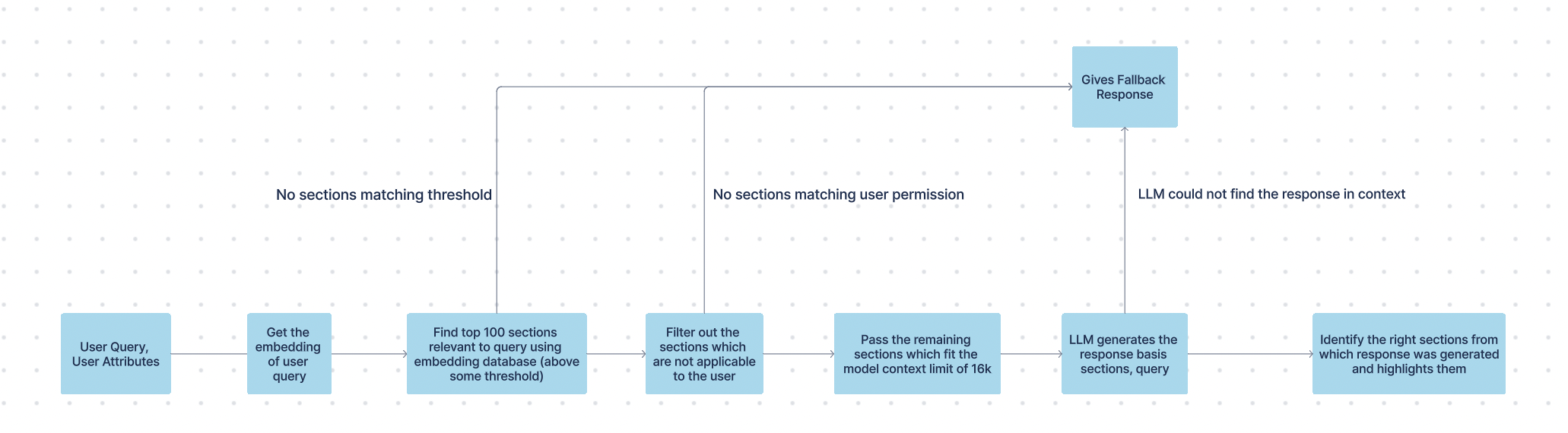
Syncing Stage
During bot syncing, embeddings are generated for:
- Policy-type articles: Each section of the parsed content.
- Question-book articles: Each question from all question-book articles.
These embeddings, created using in-house models, are then stored in the Elastic database.
Runtime Stage
The document search pipeline follows a structured approach to generate responses:
- Query Embedding: Convert the user’s query into an embedding using the in-house model.
- Retrieve Relevant Content: Identify the top matching sections or questions from the embedding database.
- User-Based Filtering: Exclude sections/questions that are not applicable to the user.
- Context Optimization: Select the top sections/questions that fit within the LLM’s context length.
- LLM Processing: Pass the refined sections/questions to the LLM along with the user query to generate a response.
- Source Identification: If the LLM provides a valid response (not “I don’t know”), another model verifies which sections contributed to the answer by checking the LLM’s response against each section.
- Highlight Extraction:
- For PDFs, PPTs, DOCX, and HTML (non-scanned documents), highlights are extracted from the relevant sections.
- For scanned documents, highlights are not displayed due to the irregular text layout, which does not align with standard rectangular highlight boxes.
This pipeline ensures that responses are contextually accurate, user-specific, and traceable to their source.
Csv search pipeline (applicable for csv/xls documents)
During bot syncing, we automatically classify CSV files into two types:
- SQL-based CSVs:
These CSVs can be converted into an SQL database, allowing us to execute standard SQL queries (filters, aggregations, etc.) for number-intensive data. The resulting tables are stored in our PostgreSQL database. - No SQL-based CSVs:
These CSVs cannot be converted into an SQL database and are treated as typical text-based documents (e.g., one column with questions and another with answers). For these, we save the document embeddings in our Elastic database.
For SQL-based CSVs, our search pipeline follows these steps to generate a final response:
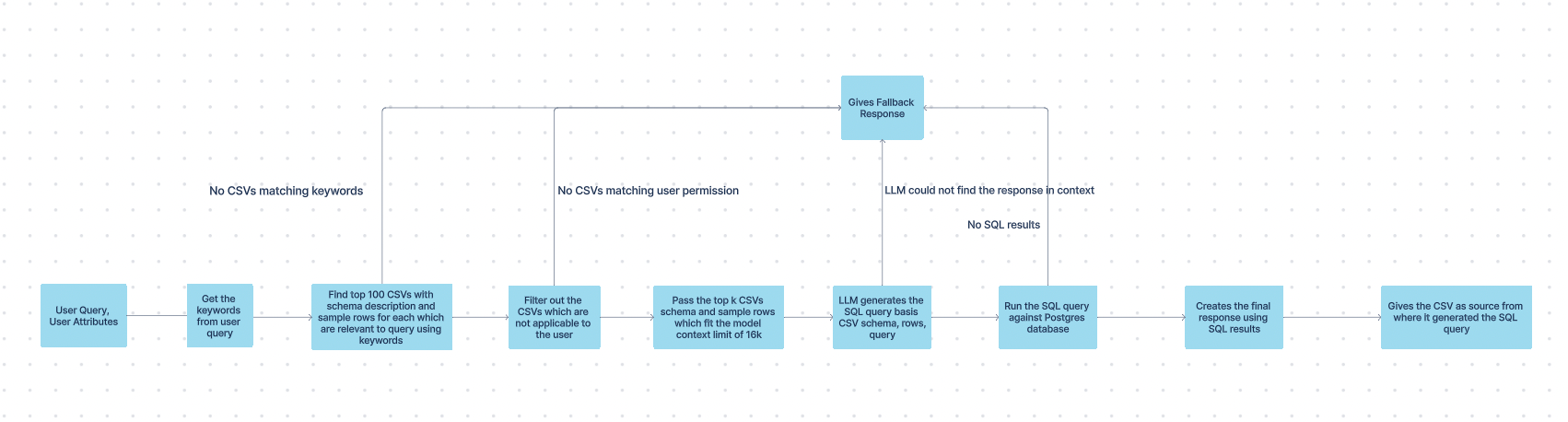
- Extract Keywords:
Extract relevant keywords from the user query. - Identify Relevant CSVs:
Retrieve the top CSV files relevant to the query. - User-based Filtering:
Exclude CSVs that are not applicable to the user. - Generate SQL Query:
Combine the remaining CSVs’ schema descriptions, sample rows, and the user query to form a valid SQL query. - Execute SQL Query:
Run the generated SQL query in our PostgreSQL database to retrieve results. - LLM Post-processing:
Pass the database results along with the user query to a large language model (LLM) to create a human-friendly response. - Response Source Annotation:
The final response is marked as sourced from a table/CSV via the SQL query.
This structured approach ensures that CSV and XLSX documents are processed effectively, whether they are SQL-compatible or text-centric.
In the No SQL CSV search pipeline, we follow these steps to generate the final response:
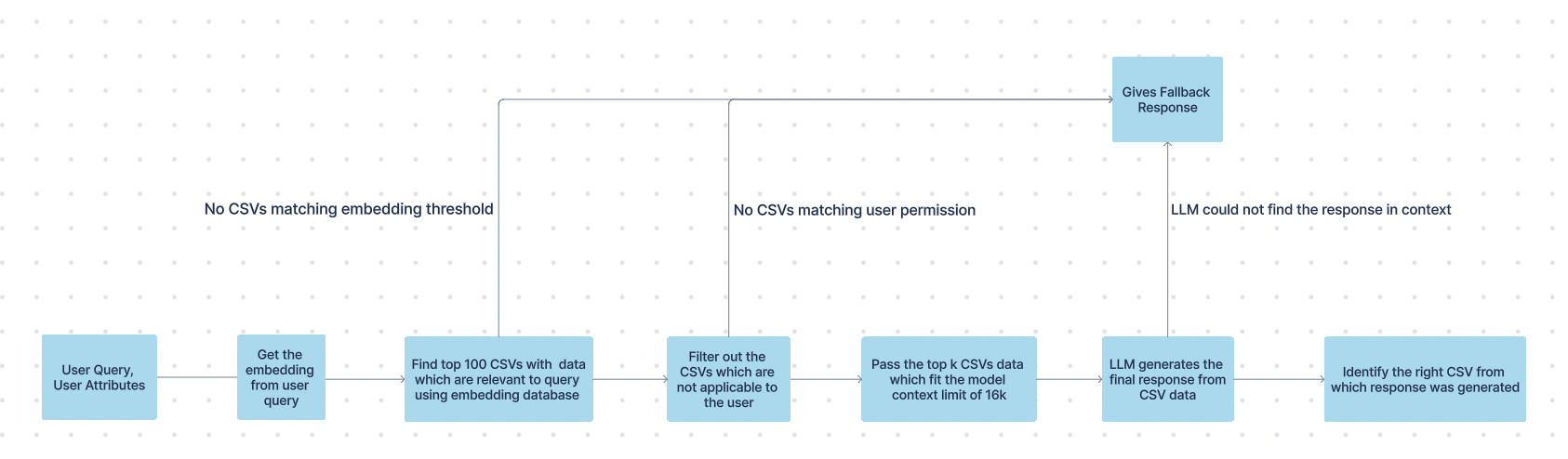
- Query Embedding:
Generate an embedding for the user's query using our in-house embedding model. - Retrieve Relevant CSVs:
Compare the query embedding with CSV embeddings stored in our Elastic database to identify the top matching CSVs. - LLM Processing:
Pass the tabular schema information from the top CSVs along with the query to a large language model (LLM). - Response Generation:
The LLM crafts a response based on the provided information. - Source Identification:
Run an additional model to determine which CSV the information originated from, and mark that CSV as the response's source.
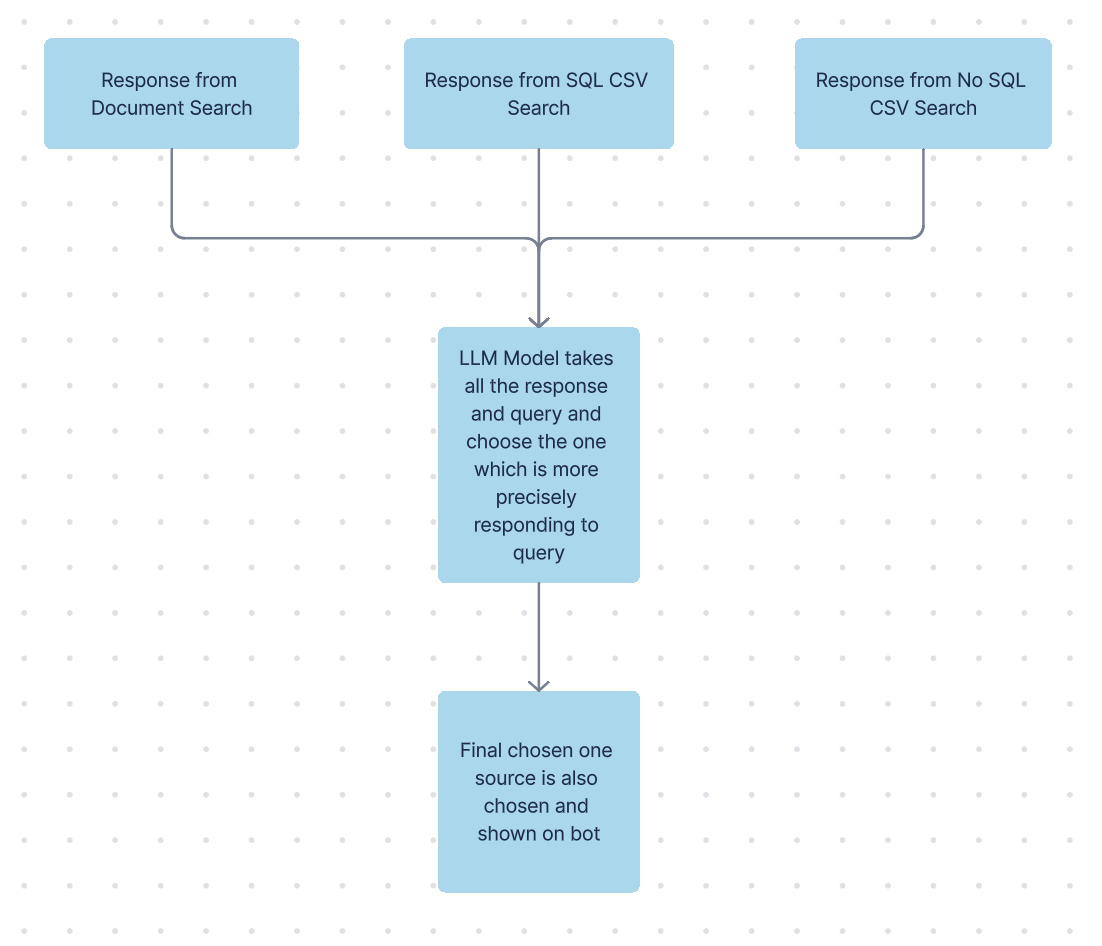
Final LLM Response Pipeline
The final LLM consolidates responses from the Document Search, SQL CSV, and No SQL CSV Search pipelines by determining the best overall answer. It handles two scenarios:
- Single Pipeline Response:
If only one pipeline returns a response, that answer is selected along with its corresponding source. - Multiple Pipeline Responses:
If responses are received from more than one pipeline (e.g., both Document Search and CSV Search), the final LLM evaluates them to choose the response that best addresses the query—ensuring it is clear, precise, and unambiguous. The source associated with the chosen response is then retained.
This approach ensures that the final output is both accurate and contextually relevant.
Post-Processing of Response
The post-processing pipeline kicks in after the LLM generates a response. It conducts validations and checks to catch any issues, ensuring only high-quality answers reach the end user. Additionally, it adds extra information and navigation elements for improved transparency and a better user experience.
Fact check model:
The fact-check validation pipeline ensures the accuracy of LLM-generated responses by verifying them against the source articles. While the LLM is tuned to generate answers strictly from provided content, there is still a risk of hallucination. In this pipeline, a fact-checking model breaks down the LLM response into multiple factual statements and cross-checks each one against the relevant articles. If several facts are found to be unsupported, the response is discarded. Otherwise, the validated response, along with its sources, is shown to the user.
Response formatting:
This supplementary pipeline enhances the LLM-generated response to improve user experience.
- Hyperlinking: Key words and phrases in the response are automatically linked to relevant company portals based on the configurations set in the dashboard.
- Formatting: If the LLM response contains HTML tags or unreadable characters, the pipeline refines the text to ensure a clean, user-friendly presentation.
This ensures responses are both informative and easy to navigate.
Additional configurations for bot responses
Leena AI offers a wide range of configuration options to tailor the final bot response to meet customer requirements. All these settings can be managed from the Knowledge Management Dashboard and are applied before the data moves to subsequent pipelines. Key configurations include:
- Multilingual Settings & Supported Languages:
Used for translations during the query preprocessing stage. - Abbreviations:
Customer-specific abbreviations applied during the document search process. - Additional Prompt Instructions:
Custom instructions for the LLM pipeline, ensuring responses align with customer needs. - AI Model Version:
Choose the specific model version for the LLM pipeline. - Disable References/Sources:
Option to disable source referencing in responses from the Knowledge Management pipeline. - Text-to-URL Mapping:
Allows specific text to be hyperlinked to internal portals for improved navigation in the post-processing stage. - Disclaimer:
A customizable message displayed after each response, reminding users that “AI can make mistakes,” applied in the post-processing pipeline. - User Attributes: (Contact Leena Admin to enable this setting)
Leverages user-specific attributes to filter relevant documents and personalise responses.
This comprehensive set of configurations empowers you to deliver a more customized and effective bot experience.