
Smart Testing in KM
Watch the tutorial
Overview
Smart Testing is a powerful feature that enables users to leverage LLMs for generating, executing, and evaluating test queries within Leena AI's Knowledge Management (KM) dashboard. It provides a seamless way to assess the accuracy of the KM agent, offering quick and valuable insights which can be further analysed to enhance its performance.
'Test queries' refers to the possible questions which users can ask from a given knowledge article in the virtual assistant.
Accessing 'Smart Testing'
Smart Testing is only accessible to KM admins.
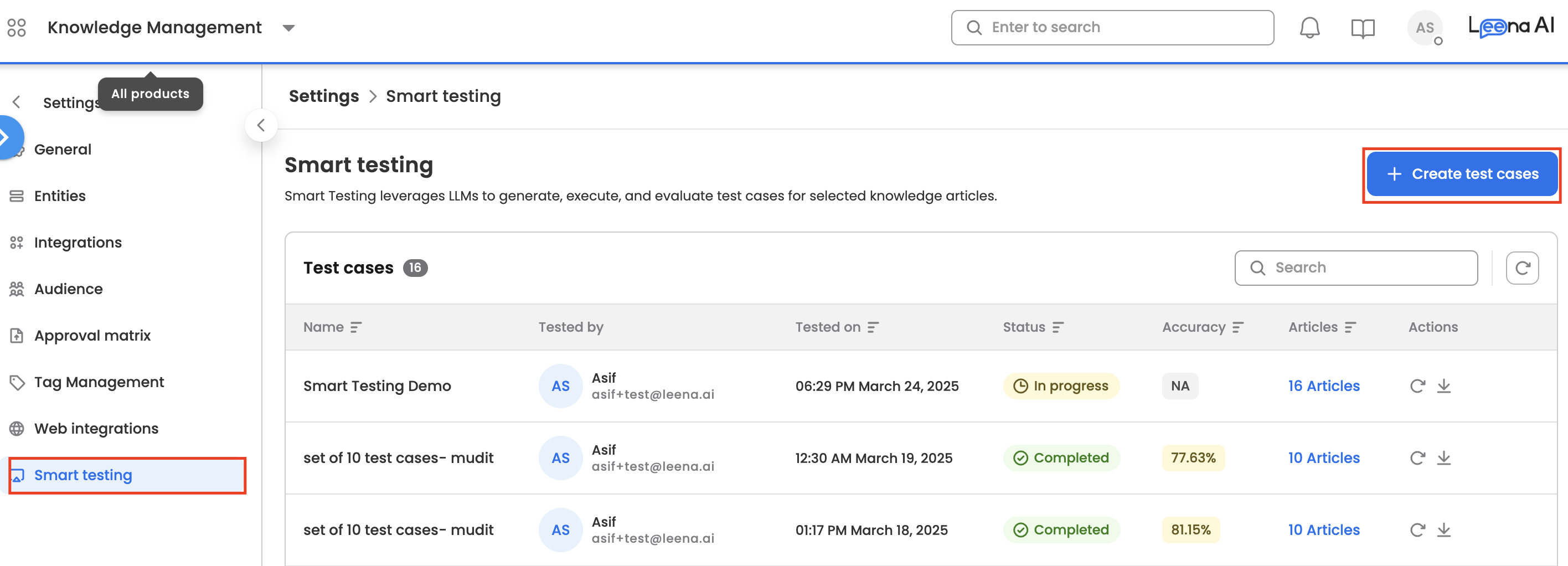
Admins can navigate to Settings >> Smart Testing.
Smart Testing Process
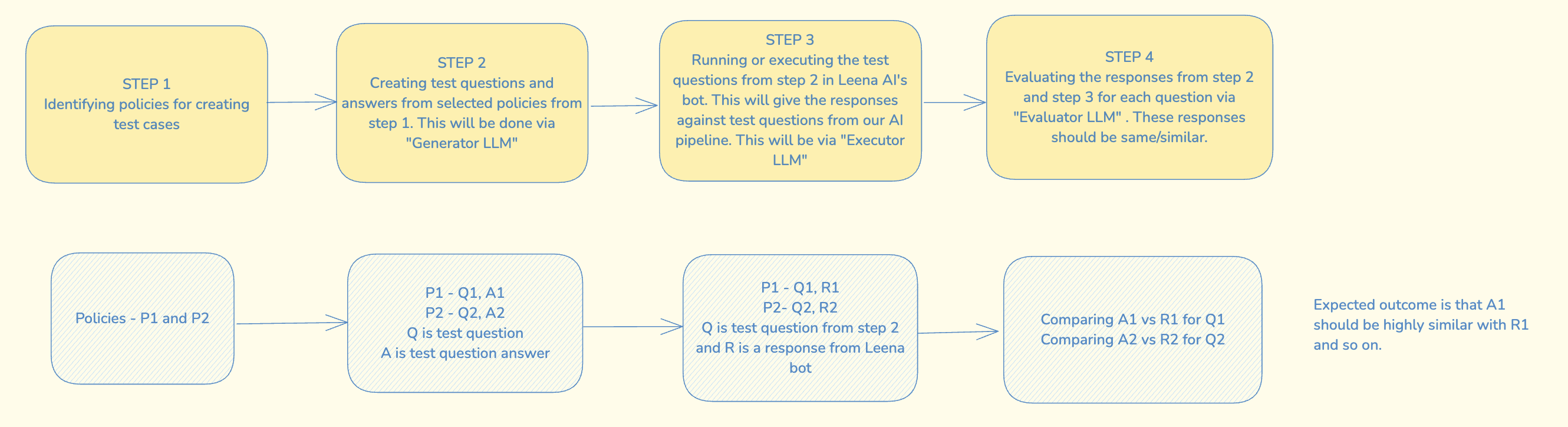
The Smart Testing workflow evaluates the accuracy of Leena AI's KM system using Large Language Models (LLMs). Here's a breakdown of each component:
Step-by-Step Explanation
-
STEP 1: Identifying Policies for Test Cases
- The first step involves selecting relevant policies (e.g., P1, P2) from the knowledge base.
- These policies will be used to create test cases, ensuring the chatbot's responses align with predefined knowledge.
-
STEP 2: Generating Test Questions and Answers
-
A Generator LLM is used to create test questions (Q) and expected answers (A) based on the selected policies.
-
Example:
P1 → Q1, A1P2 → Q2, A2
-
Here, Q is a test question, and A is the expected correct response based on the policy.
Note on Query Generation: To optimize processing speed and manage operational costs, the system is designed to pick random, representative queries from a document rather than generating questions for every single page. For large documents (e.g., 50+ pages), the LLM will select a subset of slides/pages to test. -
Importance Logic: The system uses AI to categorize articles. "Important" articles (like vacation policies or benefits) generate up to 20 questions, while "less important" articles (like technical docs or audit reports) may generate only 2 questions.
-
HTML Support: HTML articles are supported.
-
Generation Constraints:
PDFs: Are broken into 2-page chunks. Chunks are randomly selected if the document is too large to stay under the 20-question limit.
HTML: Limited to 10 sections per page, 200 words per section, and a maximum of 5,000 words total per article.
-
-
STEP 3: Executing Test Questions on Leena AI's Bot
- The generated test questions (Q1, Q2) are input into the Leena AI bot.
- The bot processes these queries and provides responses (R1, R2).
- An Executor LLM is used to simulate real user interactions and collect responses from the AI pipeline.
- Example:
P1 → Q1 → Bot Response: R1P2 → Q2 → Bot Response: R2
-
STEP 4: Evaluating the Responses
- The Evaluator LLM compares the bot’s responses (R1, R2) with the expected answers (A1, A2).
- The goal is to measure how similar the actual responses are to the expected ones.
- Final accuracy percentage is calculated as (Total "Yes" results / 3) * 100%.
- Example:
Compare A1 vs. R1Compare A2 vs. R2
Expected Outcome
The bot’s responses (R1, R2) should be highly similar to the expected answers (A1, A2). This ensures that the AI is accurately retrieving and presenting information from the knowledge base.
Summary of Key Components
| Component | Explanation |
|---|---|
| Policies (P1, P2) | Knowledge base policies used to generate test cases. |
| Generator LLM | Creates test questions (Q) and expected answers (A). |
| Executor LLM | Runs test questions on the bot and collects responses (R). |
| Evaluator LLM | Compares the bot's responses (R) with expected answers (A). |
| Expected Outcome | Bot responses should match expected answers, ensuring accuracy. |
Creating a Test Case
- Navigate to 'Smart Testing' in the KM dashboard.
- Click on the "Create test cases" CTA.
- Select the articles on which you want to generate the accuracy report. Users can also click on the row to view the articles.
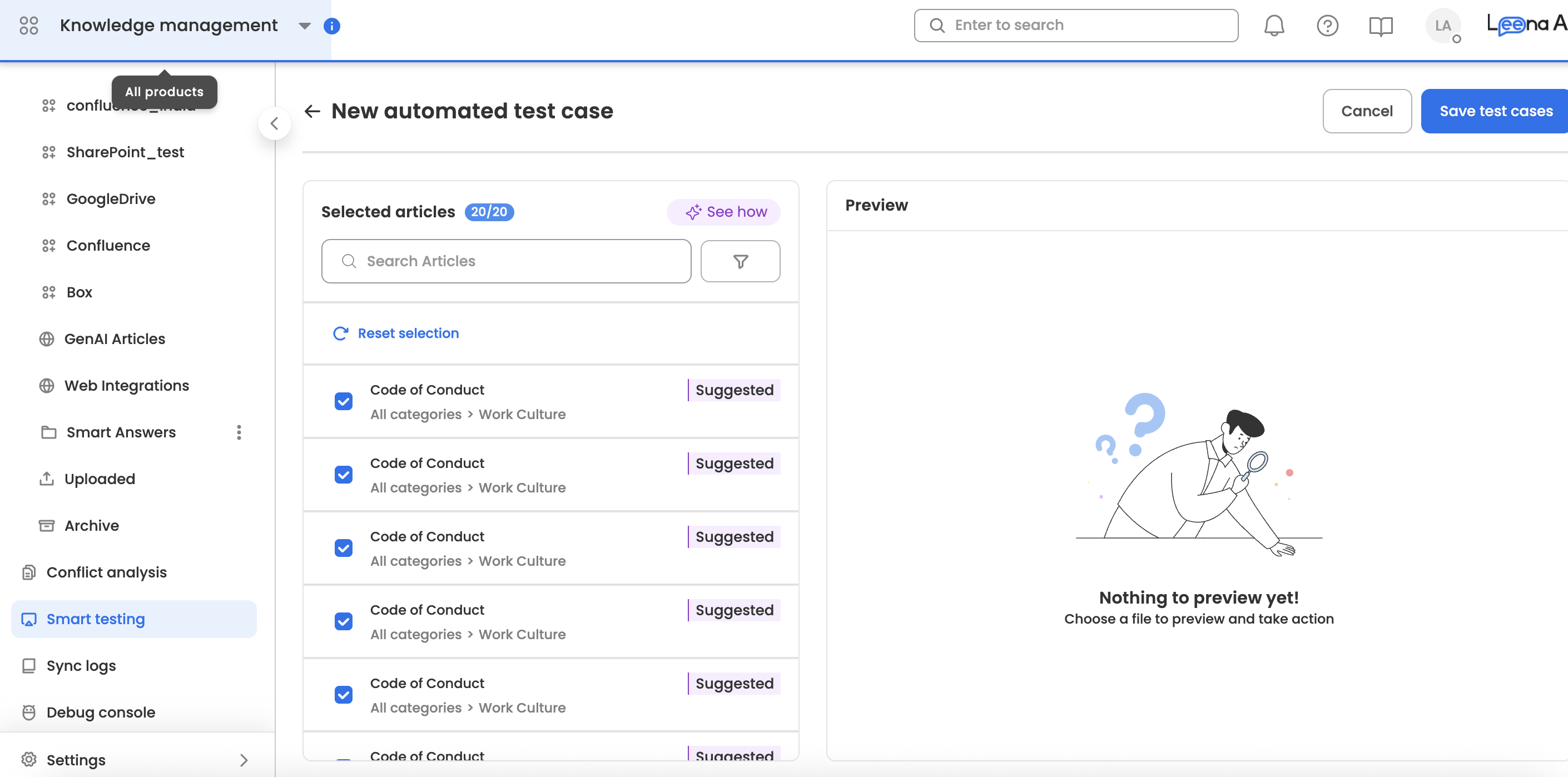
- Submit the selection.
The report will be emailed to you once processed. It can also be downloaded from the dashboard once processed. The processing time depends on the number and size of articles. Users can also click on the "reload" button to re-run the previous test case.
Notes: This feature is only available for testing the accuracy of the KM agent. This is restricted to pdf, docx, html, and ppt article types. Moreover, this does not cover personalised queries. It only contains direct questions from the knowledge articles.
System Limits & Constraints
Execution Limit: To ensure stable performance and adhere to rate limits, users can execute a maximum of 1000 test cases in a day. This is a cumulative limit across all users.User Concurrency: Only one user per account can conduct a Smart Testing session at any given time. This prevents overlapping requests and ensures data consistency.
Article Limit: Upto 100 articles can be selected in a single test run.
Document Re-testing: A document should only be added to a new test case if additions or modifications have been made to the original file. Re-testing the exact same document without changes may result in cached or inconsistent accuracy results.
Re-testing Logic : if a document is re-tested without changes, the system retrieves the previously generated questions from the KM API rather than generating new ones, though it will re-fetch answers and re-evaluate them.
Decoding the Accuracy Report
-
Article Id: This is the unique id of the article in KM.
-
Article Name: This is the name of the article in KM.
-
Question: This is the LLM-generated test question from the given article.
-
Answer: This is the LLM-generated response for the test question. In ideal scenarios, this is the expected response for the test question in the bot.
-
Sources: These are the source articles for the bot response.
-
AI Answer: This is the bot response for the test question. In ideal scenarios, this should be similar to the LLM-generated answer.
-
Status: This is the processing status of the question.
-
Accuracy: This is the calculated accuracy for the given bot response. There are 3 evaluation criteria the bot response needs to pass to be 100%:
- Content Accuracy: Does the Actual Response contain accurate information that matches the facts presented in the Acceptable Response? We are just checking whether information present in the Actual Response matches information in the Acceptable Response.
- Completeness: Does the Actual Response cover most of the key points and details found in the Acceptable Response? We just check whether most of the information in the Acceptable Response is present in the Actual Response or not.
- Relevance of Information: Does the Actual Response avoid introducing unnecessary or irrelevant information? We are just checking whether all information present in the Actual Response is relevant to the query or not.
If a response passed all 3 criteria, it is considered 100% accurate. If it passed only 2 criteria, it is 66% accurate. For 1 criterion, 33% accurate. For no criteria, 0% accuracy. The overall accuracy is the average of the accuracy of all the queries.
-
Content Accuracy: This is the status of the first criteria of evaluation.
-
Content Accuracy Reason: This is the LLM reasoning when evaluating a response on 'content accuracy'.
-
Completeness: This is the status of the second criteria of evaluation.
-
Completeness Reason: This is the LLM reasoning when evaluating a response on 'completeness'.
-
Relevance: This is the status of the third criteria of evaluation.
-
Relevance Reason: This is the LLM reasoning when evaluating a response on 'relevance'.
-
Error: This column might be present if there is any system error in test cases evaluation.
Troubleshooting
Test Case Stuck in "Processing" If a document remains in the processing state for more than 2 hours, it may prohibit the execution of further test cases.
Workaround: Please contact the backend team (via your designated POC) to manually cancel the stuck request. Once canceled, you will be able to initiate a new test case.